 I recently came across the presentation The Positive Trust Model and Whitelists, by Wyatt Starnes of Signacert, a company that specialises in whitelisting solutions (get the video here). I thought the presentation made some good points, worth repeating here, and extending with other opinions (of which there are many).
I recently came across the presentation The Positive Trust Model and Whitelists, by Wyatt Starnes of Signacert, a company that specialises in whitelisting solutions (get the video here). I thought the presentation made some good points, worth repeating here, and extending with other opinions (of which there are many).
Whitelisting, like virtualisation, is a mainframe concept largely forgotten in the era of personal computing, recently rediscovered in our modern IT environment. There are various forms of whitelisting for security purposes, for example in the context of combating email fraud and SPAM, but here we will be concerned with application whitelisting - a method to ensure that only approved applications and their associated executables are permitted to run on a given machine.
John W. Thompson, CEO of Symantec, from his 2008 RSA keynote, supported whitelisting in the face of growing malware diversity (quoted by Starnes)
From where I sit, a few things are very, very, clear. If the growth of malicious software continues to outpace the growth of legitimate software, techniques like whitelisting, where we identify and allow only the good stuff to come in, will become much, much, more critical.
This is a telling statement from the CEO of a company whose cash cow is desktop AV software, the epitome of blacklisting technology. Thompson, and other companies whose business models are firmly based on blacklisting, now agree that whitelisting as a malware defence is an idea whose time has come.
Malware is Increasing
Blacklisting is not really about maintaining a list of prohibited software, but rather maintaining a database of malware signatures to evaluate the state of software through scanning. Software is blacklisted when it is identified to have characteristics identical or similar to known malware. And this is the key point - known malware. The successful and timely identification of malware depends on the rapid identification, production and distribution of updates to signature databases.
Over the last year an inflection point was reached where malware crossed over as being produced in greater quantities than legitimate software. We are heading to the same state of affairs in email where SPAM dominates the number of legitimate messages. Starnes depicted this situation as follows
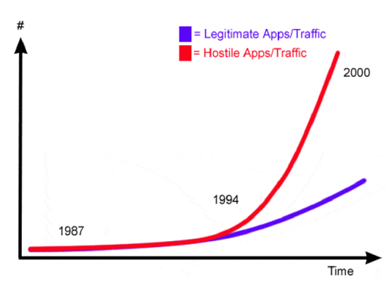
The slide heading for the graphic above is Chase the Infinite or Confirm the Finite? The question asks whether it is a better IT defensive strategy to attempt to screen a wide and increasing variety of malware, or focus on maintaining the current integrity of the known components of your IT system.
A presentation from Martin Fréchette of Symantec Labs, given at RAID 2007, provides more background. First he has a more detailed graph on the number of new threats, which are essentially increasing exponentially.
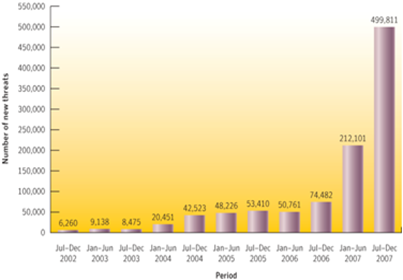
By the end of 2008 there were approximately 1,000,000 known examples of malware, over 2/3 of which had been produced in 2008. That is, 2008 saw more malware produced than all previous years combined. While this sounds alarming, Fréchette notes that part of the reason known malware has been increasing rapidly is due to better detection methods, in particular honeypots and malware sensor networks.
But malware is also increasing due to a change in strategy of the malware industry. Fréchette observes a shift from a mass distribution of a small number of threats to micro distribution of millions of distinct threats, more recently referred to as targeted attacks. Symantec has observed single days where 10,000 new virus strains have been produced, mainly through a technique known as server-side polymorphism, which can automatically regenerate malware strains.
Fréchette notes that the micro distribution strategy is greatly reducing the effectiveness of classic malware signature detection. Even just a few years ago a single signature could be expected to protect 10,000 users whereas today that expectation has dropped to less than 20 users. That is, malware attacks are so specific that signatures serve only to protect small groups of users. Thus signatures must be produced in vast numbers to protect the broader user community.
The Twilight of Blacklisting
 The AV blacklisting industry has reached a point of diminishing returns - the marginal value of producing additional signatures is minimal, but the underlying model can offer no more advice than to simply keep doing exactly that. The AV signature cycle of detect-produce-distribute is being overwhelmed, and the effectiveness of AV solutions (that is, the fraction of known malware that is detectable) is decreasing. Equivalently, the false positive rate is increasing, and consumers are getting less protection than they expect.
The AV blacklisting industry has reached a point of diminishing returns - the marginal value of producing additional signatures is minimal, but the underlying model can offer no more advice than to simply keep doing exactly that. The AV signature cycle of detect-produce-distribute is being overwhelmed, and the effectiveness of AV solutions (that is, the fraction of known malware that is detectable) is decreasing. Equivalently, the false positive rate is increasing, and consumers are getting less protection than they expect.
There is a significant burden on networks to distribute signatures and also on platforms to perform scanning. Scanning each and every file is neither feasible nor effective. In October last year I posted some remarks on a new patent granted to Kaspersky for a risk-based approach to AV scanning which described criteria (risk factors) for reducing the amount of file scanning. In July last year Robert Vamosi of CNET reported that Norton will also follow a risk-based approach in 2009 with their products, creating a trust index that will be used to judge how often files are scanned. However when I posed the question Would you support less malware scanning to improve user performance? over at LinkedIn the resounding answer was No.
Blacklisting only has a future as a primary security defense if we can actually find ways to do less of it and still retain a low false positive rate. But this sounds like squaring the circle.
Charge of the White Brigade
Enter Whitelisting. Rather than attempting to determine if an arbitrary file (executable) is malicious based on signatures or other criteria, whitelisting creates approved copies of software and simply checks whether the current copy of a binary is the same as its approved copy. Software that is not on the approved list are blocked from running, period. Starnes represents the whitelist production process as follows
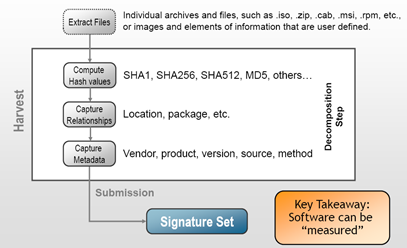
There is a significant reliance on hashing and signatures for trust, where signature here means a PKI signature, not a blacklist signature. Unauthorized change in a file is detected (with high probability) by a change in its associated hash which will in turn cause the signature verification step to fail.
Notice that the hash-sign paradigm of trust here detects changes in software, and does not indicate the absence of security vulnerabilities in software. The point of whitelisting is not to prevent insecure software from being unintentionally loaded onto desktops through an authorized software distribution process. It strives to prevent software (whether secure or no) from being loaded on your desktop in an unauthorized manner. Whitelisting makes sure that the assumed good software stays good, and keeps out the unknown and potentially malicious, software. In essence whitelisting is about maintaining a known software state, and implementing authorized change from one known state to another.
Whitelisting therefore requires a repository of trusted software, which Starnes refers to as a collection of platinum images (you can pick your favourite precious metal or stone).
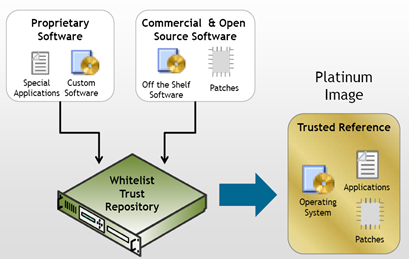
So while blacklists require a signature database and other contextual information for assessing potential malware, whitelisting also requires a repository for proper functioning. The difference is that whitelisting mainly performs comparisons between software to be executed and its respective repository image (a simple check), while the blacklisting database is used to scan and assess the security of the software in question (a more difficult operation).
The size of the whitelist repository grows as a function of the software base supported, while the blacklist database grows in proportion to the amount of known malware - which we have just seen is increasing at an unchecked rate. Chase the infinite or confirm the finite?
While the whitelist model is compelling, in practice it requires significant work to deploy. Assessing and creating the initial list of approved software is a significant task, and would be greatly assisted by existing CMDB implementation efforts in a company. Also, the success of whitelisting is wedded to its tight integration into the software patching and upgrading process. The repository will be in constant flux since software itself is in a constant state of (approved and required) change.
The Way Forward
Not unexpectedly, there is quite a bit of hype around whitelisting, mainly concerning its magical powers to cure security conundrums such as zero-day attacks and endless patching cycles for example. But it will do neither of these two things. Whitelisting does not prevent developers from coding buffer overflows into applications, nor does it prevent malicious attacks from exploiting them. Developers will still require security coding education, and identified vulnerabilities will still require patching.
Nonetheless, the major vendors agree that we will require blacklisting in some form, but whitelisting may become the new leading actor. Bit9 (a whitelist provider) and Kaspersky (a blacklist provider) have teamed up to provide a hybrid consumer solution, where software is scanned only when it is not present on a whitelist. This is not quite whitelisting as intended but it represents the first step in a gradual integration, and more importantly, a way to preserve the blacklisting revenue model. One way or another, whitelists will be coming to a desktop near you soon.

You can find the research used to produce this post as a FreeMind mindmap rendered into Flash here.
Related Posts
 In my post Risk Factors for AV Scanning, I discussed a recent patent filing by Kaspersky related to reducing the amount of malware scanning based on various file properties. One of those properties was whether the file is packed or not, since packed files are to be treated more suspiciously than plain unpacked files.
In my post Risk Factors for AV Scanning, I discussed a recent patent filing by Kaspersky related to reducing the amount of malware scanning based on various file properties. One of those properties was whether the file is packed or not, since packed files are to be treated more suspiciously than plain unpacked files. 





























{kind=link}
{kind=link}